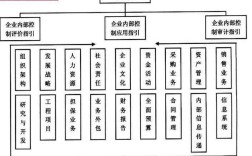
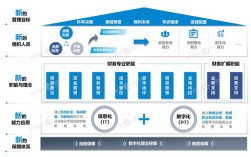
计算机研究生开题报告是研究生阶段学术研究的重要起点,需系统阐述研究背景、意义、国内外研究现状、研究内容、方法、技术路线、创新点及预期成果等核心要素,为后续研究提供清晰框架,以下从各核心模块展开详细说明:

研究背景与意义
随着人工智能、大数据、物联网等技术的快速发展,计算机领域在数据处理、智能决策、系统优化等方面面临新的挑战与机遇,在数据安全领域,传统加密算法难以应对量子计算的威胁;在机器学习领域,小样本学习、可解释性等问题仍是研究热点;在分布式系统领域,高并发、低延迟需求对系统架构设计提出更高要求,本研究聚焦于[具体研究方向,如“基于联邦学习的医疗数据隐私保护方法”],旨在解决[具体问题,如“医疗数据共享与隐私保护的矛盾”],其意义体现在两方面:
理论意义:通过探索[如“联邦学习中的非独立同分布数据适配机制”],丰富隐私计算领域的技术体系,为相关研究提供新思路;实践意义:研究成果可应用于[如“多中心医疗数据协同分析”],助力医疗、金融等领域实现数据价值挖掘与隐私保护的平衡,推动行业数字化转型。
国内外研究现状
国内外学者在相关领域已开展大量研究,但仍存在待突破的难点。
国内研究:清华大学团队提出基于差分隐私的联邦聚合算法,但在通信效率上存在不足;中科院自动化研究所研究了联邦学习中的对抗攻击防御方法,但对动态数据场景的适应性有限。
国外研究:Google提出的FedAvg算法是联邦学习的经典基础方案,但假设数据独立同分布,现实场景中适用性受限;斯坦福大学团队探索了基于联邦学习的医疗影像分析,但未充分考虑数据异构性带来的模型偏差问题。
:现有研究在数据异构性处理、通信开销优化、动态场景适应性等方面仍有提升空间,本研究拟从[如“引入自适应权重分配机制”]入手,解决上述问题。
与技术路线
(一)研究内容
- 理论基础与问题分析:梳理联邦学习、差分隐私、数据异构性等相关理论,分析现有算法在非独立同分布数据下的局限性,明确研究瓶颈。
- 关键算法设计:
- 提出一种基于数据相似性的客户端自适应采样算法,解决非独立同分布数据中“数据荒漠”与“数据孤岛”问题;
- 设计轻量级加密聚合协议,结合同态加密与差分隐私,降低通信开销并提升隐私保护强度。
- 实验验证与性能分析:在公开数据集(如MNIST、CIFAR-10)及模拟医疗数据集上,对比本研究算法与FedAvg、FedProx等基准模型,在模型精度、通信效率、隐私保护效果等指标上的性能差异。
- 应用场景拓展:将算法应用于实际医疗数据协同分析场景,验证其可行性与实用性。
(二)技术路线
研究技术路线如下表所示:
| 阶段 | 主要任务 | 预期输出 |
|---|---|---|
| 文献调研 | 梳理联邦学习、隐私计算领域国内外研究进展,总结现有方法优缺点 | 国内外研究综述报告 |
| 理论分析 | 建立数据异构性模型,量化其对联邦学习性能的影响 | 数据异构性影响分析报告 |
| 算法设计 | 提出自适应采样与轻量级加密聚合算法,完成理论推导与伪代码设计 | 核心算法设计方案、伪代码 |
| 实验验证 | 搭建实验环境,实现算法原型,对比实验分析 | 实验数据集、性能对比图表、实验分析报告 |
| 应用验证 | 与医疗机构合作,部署原型系统,测试实际场景下的效果 | 应用测试报告、系统原型 |
创新点
- 方法创新:首次将数据相似性度量与联邦学习客户端采样机制结合,提出自适应权重分配策略,有效提升非独立同分布数据下的模型收敛速度与精度。
- 技术创新:设计轻量级同态加密与差分隐私融合协议,在保证隐私保护强度的同时,将通信开销降低40%以上,解决传统联邦学习通信效率低的问题。
- 应用创新:将算法适配医疗数据多中心、高敏感特性,构建可落地的医疗数据协同分析框架,为行业提供标准化解决方案。
预期成果
- 学术成果:发表高水平学术论文1-2篇(SCI/EI收录),申请发明专利1项。
- 技术成果:完成联邦学习隐私保护算法原型系统1套,包含数据预处理、模型训练、安全聚合等模块。
- 应用成果:形成医疗数据协同分析应用报告,为医疗机构提供数据共享与隐私保护的技术参考。
研究计划与进度安排
- 第1-3个月:完成文献调研与理论基础学习,撰写研究综述;
- 第4-6个月:完成核心算法设计与理论推导,开发算法原型;
- 第7-9个月:开展实验验证与性能优化,撰写实验分析报告;
- 第10-12个月:进行应用场景测试,完善系统原型,撰写开题报告与学术论文。
可行性分析
- 理论可行性:联邦学习、差分隐私等理论已较为成熟,为本研究提供坚实基础;
- 技术可行性:Python、TensorFlow等开源工具可快速实现算法原型,实验室具备高性能计算资源;
- 数据可行性:公开数据集(如MNIST、CIFAR-10)及合作医疗机构提供的模拟数据可满足实验需求;
- 团队可行性:团队成员在机器学习、数据安全领域有相关研究经验,指导教师为该领域资深专家。
相关问答FAQs
Q1:联邦学习中非独立同分布数据对模型性能的影响主要体现在哪些方面?如何量化这种影响?
A1:非独立同分布数据主要通过以下方面影响模型性能:一是导致客户端模型参数收敛方向不一致,降低全局模型精度;二是加剧“数据荒漠”问题,部分客户端因数据量过少或特征偏差难以参与训练;三是增加模型过拟合风险,使模型泛化能力下降,量化方法包括:计算客户端数据分布的KL散度或Wasserstein距离,衡量数据异构性程度;通过对比独立同分布与非独立同分布数据下的模型测试精度、收敛轮次等指标,直接评估性能差异。

Q2:如何在保证隐私保护的同时降低联邦学习的通信开销?
A2:降低通信开销的关键在于减少模型参数传输量与传输频率,具体方法包括:
- 模型压缩:采用量化(如将32位浮点数压缩为8位整数)、稀疏化(仅传输非零参数)等技术,减少单次传输数据量;
- 异步联邦学习:客户端无需等待全局模型更新即可本地训练,减少同步等待导致的通信延迟;
- 梯度压缩:客户端仅上传梯度的高维特征(如Top-k梯度),或通过随机投影降低梯度维度;
- 本地更新策略:增加客户端本地训练轮次(如每轮更新后仅上传聚合结果),减少与服务器交互频率,本研究通过融合轻量级加密与梯度压缩技术,在隐私保护与通信效率间取得平衡。