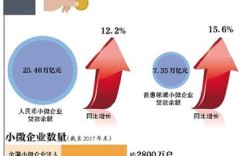
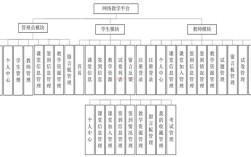
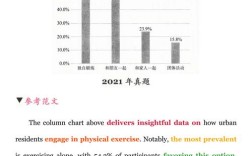
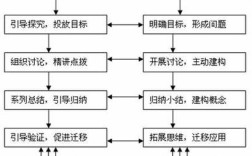
小论文研究背景与目的

在当前全球化与信息化深度融合的时代背景下,数据已成为驱动社会经济发展的核心生产要素,其战略价值日益凸显,随着数字技术的迅猛发展,各行各业正经历着从“经验驱动”向“数据驱动”的深刻转型,大数据、人工智能、云计算等新兴技术的应用场景不断拓展,为传统产业升级和新兴业态创新提供了强大动力,数据规模的爆炸式增长与数据价值的深度挖掘之间仍存在显著差距,如何高效整合、分析并利用海量数据,成为学术界与产业界共同关注的核心议题,在此背景下,数据科学与相关交叉学科的研究显得尤为重要,其研究成果不仅能够推动技术进步,更能为政策制定、企业管理、公共服务等领域提供科学依据,助力社会高质量发展。
从现实需求来看,数据驱动决策已成为提升组织竞争力的关键手段,以企业为例,通过数据分析,企业可以精准把握市场需求、优化供应链管理、降低运营成本,甚至实现商业模式创新,零售业利用消费者行为数据实现个性化推荐,金融业依托信用风险评估模型控制风险,医疗领域通过临床数据分析提升诊断准确率,数据应用过程中也面临诸多挑战:数据质量参差不齐、数据孤岛现象严重、数据安全与隐私保护风险突出,以及数据分析模型的可解释性不足等问题,制约了数据价值的充分释放,不同行业、不同规模的组织在数据能力建设上存在显著差异,中小企业往往因技术、资金和人才限制,难以充分发挥数据潜力,这些问题的存在,凸显了开展数据驱动相关研究的必要性与紧迫性。
从理论发展角度看,现有数据科学研究仍存在一定局限性,传统数据分析方法在处理高维、非线性、动态变化的数据时效果有限,难以满足复杂场景下的需求;多源异构数据融合、实时数据处理、因果推断等前沿技术尚未形成成熟的理论体系和方法框架,数据伦理与治理研究相对滞后,缺乏系统性的规范和标准,导致数据滥用、算法歧视等现象时有发生,深化数据驱动领域的理论研究,探索新的分析模型、算法框架和应用范式,不仅能够丰富学科内涵,更能为实践中的问题解决提供理论支撑。
基于上述背景,本研究旨在通过多维度、系统性的分析,探索数据驱动在特定场景下的应用路径与优化策略,并针对现有问题提出解决方案,具体而言,研究目的包括以下三个方面:

本研究旨在揭示数据驱动决策的核心机制与影响因素,通过理论梳理与实证分析,构建数据价值转化路径模型,识别影响数据应用效果的关键因素(如数据质量、技术能力、组织文化等),并探究各因素之间的相互作用关系,这一研究有助于深化对数据驱动规律的认识,为组织提升数据能力提供理论指导。
本研究致力于开发适用于复杂场景的数据分析新方法,针对传统模型在处理多源异构数据、实时动态数据等方面的不足,结合机器学习、深度学习等技术,提出改进的分析算法或框架,并通过案例验证其有效性和实用性,在供应链管理场景中,构建融合外部环境数据与内部运营数据的动态预测模型,以提高需求预测精度和库存周转效率。
本研究试图构建数据驱动的风险防控与治理框架,针对数据安全、隐私保护、算法公平性等问题,提出兼顾效率与安全的治理策略,包括数据分级分类管理、隐私计算技术应用、算法审计机制等,为推动数据要素市场的健康发展提供参考。
为实现上述目的,本研究将采用定量与定性相结合的研究方法,通过问卷调查、实验设计等方式收集数据,运用统计分析方法验证理论假设;通过案例研究、深度访谈等方式,深入剖析数据应用中的典型问题与成功经验,确保研究结论的科学性和实践指导意义。

在实践层面,本研究的成果有望为企业、政府部门及其他组织提供可操作的决策参考,帮助其优化数据资源配置,提升数据应用效能,通过推动数据驱动理论与实践的结合,为数字经济的创新发展注入新动能。
相关问答FAQs
Q1:数据驱动研究中最常见的挑战有哪些?如何应对?
A1:数据驱动研究中的常见挑战包括数据质量问题(如缺失值、异常值)、数据孤岛导致的数据整合困难、模型可解释性不足,以及数据安全与隐私保护风险,应对策略包括:采用数据清洗与预处理技术提升数据质量;通过数据中台、联邦学习等打破数据孤岛;结合可解释AI方法(如LIME、SHAP)增强模型透明度;利用差分隐私、同态加密等技术保障数据安全,建立跨学科团队、加强数据伦理培训也是应对挑战的重要途径。
Q2:如何评估数据驱动项目的实施效果?
A2:评估数据驱动项目效果需结合定量与定性指标,定量指标包括业务指标(如效率提升率、成本降低幅度)、技术指标(如模型准确率、数据处理速度)和经济效益指标(如投资回报率),定性指标则涉及用户满意度、组织文化转变、决策流程优化等,可采用对比分析法(如实施前后的数据对比)、A/B测试(如不同策略的效果对比)以及长期跟踪评估(如可持续性分析)综合衡量项目价值,需建立动态评估机制,根据反馈持续优化项目方案。