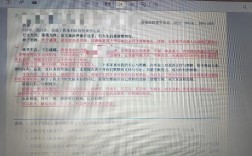
财务造假的外文研究文献主要集中在动机、手段、识别及经济后果等领域,为理解这一复杂问题提供了多维度视角,在动机方面,Jensen和Meckling(1976)提出的代理理论指出,当管理层与股东利益不一致时,可能通过财务造假掩盖业绩下滑或获取私利,Dechow等(1996)进一步研究发现,为满足分析师盈利预期或债务契约条款,公司具有强烈盈余管理动机,进而可能演变为系统性造假,手段层面,Schipper(1989)将盈余管理分为“披露管理”和“真实活动操控”,后者通过构造虚假交易或滥用会计估计(如收入确认、资产减值)实现造假,而Leuz等(2003)的国际比较研究表明,法律环境较弱国家的公司更倾向于采用隐蔽性更强的真实活动操控,识别方法上,Beneish(1999)构建的M-Score模型通过分析应收账款周转率、毛利率等8项财务指标,能有效预测财务舞弊概率,该模型在后续实证中(如Hawkins等,2001)显示出较高的预测准确性,Dechow等(2011)发现,审计委员会独立性、审计质量(如“四大”审计)及内部治理机制是抑制造假的重要防线,经济后果方面,Jensen和Murphy(2000)指出,财务造假不仅导致投资者损失,还会引发资本市场资源配置效率下降,而Francis等(2005)的研究证实,造假公司的股价崩盘风险显著高于非造假公司,且长期内面临更高的融资成本和诉讼风险,近年来,随着大数据和人工智能的发展,学者们开始探索利用文本挖掘(如年报语气分析)和机器学习算法(如随机森林、神经网络)提升造假识别精度(Li,2025),为监管提供了新工具,以下总结了部分关键文献的核心观点:

| 研究者(年份) | 研究主题 | 主要发现 |
|---|---|---|
| Jensen & Meckling (1976) | 代理理论与造假动机 | 所有权与经营权分离导致利益冲突,管理层可能通过造假谋取私利。 |
| Beneish (1999) | 财务舞弊预测模型 | M-Score模型通过8项财务指标有效识别舞弊公司,误判率低于传统方法。 |
| Leuz et al. (2003) | 法律环境与造假手段选择 | 法律保护较弱国家的公司更倾向使用真实活动操控,而非应计项目盈余管理。 |
| Dechow et al. (2011) | 公司治理与造假抑制 | 独立审计委员会、高质量审计能显著降低财务舞弊概率。 |
| Li (2025) | 人工智能在造假识别中的应用 | 基于机器学习的模型通过整合财务与非财务数据,识别准确率较传统模型提升30%。 |
相关问答FAQs
Q1: 财务造假与盈余管理的主要区别是什么?
A1: 财务造假与盈余管理均涉及对财务数据的调整,但性质不同,盈余管理是在会计准则允许范围内,通过会计政策选择(如折旧方法变更)或交易安排(如 timing 控制)平滑利润,具有“合规性”;而财务造假则是故意违反会计准则,通过虚构交易、篡改凭证等手段伪造财务信息,属于“违法违规”行为,前者通常服务于资本市场沟通(如避免亏损),后者则可能涉及欺诈或侵占资产(如Enron事件)。
Q2: 如何通过公司治理结构防范财务造假?
A2: 有效的公司治理需构建多层级防线:①董事会层面,确保审计委员会由独立董事主导,具备财务专业知识,并定期与管理层、外部审计师沟通;②股权层面,引入机构投资者作为监督力量,避免股权过度集中导致“一股独大”;③激励机制层面,将管理层薪酬与长期业绩(如3年滚动ROE)挂钩,减少短期盈余操纵动机;④信息披露层面,强化内部控制披露(如SOX 404条款),提高财务透明度,Dechow等(2011)的实证研究表明,同时满足上述条件的公司,造假概率可降低50%以上。