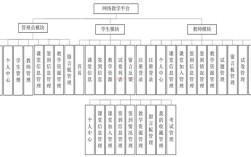
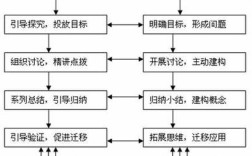
电子商务发展研究方法是一个系统性、多维度的分析框架,旨在通过科学的方法论探究电子商务的运行规律、发展趋势及影响因素,随着数字经济的深入发展,电子商务已从单一的在线交易模式演变为涵盖社交电商、直播电商、跨境贸易等多元业态的复杂生态系统,其研究方法也需结合定量与定性、宏观与微观、静态与动态的分析视角,形成多层次、跨学科的研究体系,以下从研究设计、数据采集、分析方法及工具应用等方面展开详细阐述。

研究设计阶段:明确框架与逻辑起点
研究设计是电子商务发展的基础,需明确研究目标、问题边界及理论框架,研究目标应聚焦具体方向,如用户行为分析、平台竞争策略、政策影响评估或技术驱动效应等,若研究“直播电商对消费者购买决策的影响”,需进一步细化问题:直播间的互动设计、主播信任度、价格感知等因素如何作用于转化率?理论框架的构建需结合相关学科理论,如技术接受模型(TAM)、消费者行为理论、产业组织理论等,为假设提出提供支撑,基于TAM理论可假设“感知易用性 positively 影响用户使用意愿”,再通过实证检验其有效性,研究设计需区分探索性研究与验证性研究:探索性研究适用于新兴领域(如AI在电商中的应用),多采用案例访谈、焦点小组等方法;验证性研究则侧重检验既有理论(如电商平台的网络效应),需通过大规模数据量化分析。
数据采集方法:多源数据融合与质量控制
数据是电子商务研究的核心,采集方法需兼顾全面性与准确性,主要分为定量数据与定性数据两大类。
定量数据采集
定量数据通过结构化信息揭示规律,常见来源包括:
- 平台数据:电商平台(如淘宝、京东)提供的用户行为日志(点击流、停留时长、购买记录)、交易数据(GMV、客单价、复购率)及商家运营数据(广告投放、库存周转),此类数据需通过API接口或数据爬虫获取,但需遵守平台规则与《网络安全法》对数据隐私的要求。
- 第三方数据:艾瑞咨询、易观分析等机构发布的行业报告,或QuestMobile、CNNIC等用户行为监测数据,涵盖市场规模、用户画像、渗透率等宏观指标。
- 调研数据:通过问卷设计收集一手数据,适用于研究用户态度、偏好等主观变量,采用李克特五级量表测量“消费者对直播电商的信任度”,并通过分层抽样确保样本代表性(如按年龄、地域、消费水平划分)。
定性数据采集
定性数据用于挖掘深层动机与机制,常用方法包括:

- 深度访谈:对消费者、商家、平台运营者进行半结构化访谈,了解其对电商模式的认知与体验,访谈中小商家可揭示“直播带货的成本结构及盈利痛点”。
- 案例研究:选取典型企业(如拼多多、SHEIN)或现象(如“618购物节”)进行纵向或横向分析,总结其成功经验或失败教训,案例研究需结合内部文档、公开报道及实地观察,确保数据三角验证。 分析**:对社交媒体评论(如微博、小红书)、用户评价进行文本挖掘,提取情感倾向与关键词,通过Python的Jieba分词分析“消费者对跨境电商物流的抱怨点”,识别“清关慢”“关税高”等高频问题。
数据质量控制
无论何种数据源,均需处理缺失值、异常值与重复数据,通过均值填充法处理问卷中的缺失值,或通过3σ原则剔除用户行为数据中的极端值(如单次点击次数超过均值3倍的数据),需进行信效度检验:问卷数据的信度可通过Cronbach's α系数评估(一般需>0.7),效度则通过因子分析验证结构效度。
分析方法:定量与定性结合的多元路径
数据分析是验证假设、揭示规律的关键,需根据研究问题选择合适的方法,形成“描述-诊断-预测-优化”的完整分析链条。
定量分析方法
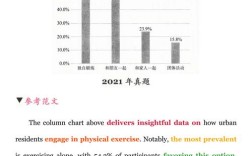
- 描述性统计:通过均值、中位数、标准差等指标概括数据特征,如“2025年中国直播电商用户平均每月观看时长为12.5小时,标准差3.2小时”,反映用户行为的集中趋势与离散程度。
- 推断性统计:包括假设检验与回归分析,通过t检验比较“有直播购物经历”与“无直播购物经历”用户的客单价差异;通过多元线性回归分析“价格折扣、主播知名度、互动频率”对购买意愿的影响权重,构建模型:
[ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \beta_3X_3 + \varepsilon ]
(Y)为购买意愿,(X_1)为价格折扣,(X_2)为主播知名度,(X_3)为互动频率,(\beta)为回归系数。 - 高级建模:针对复杂问题可采用结构方程模型(SEM)分析潜变量关系(如“平台信任度”对“用户忠诚度”的直接与间接效应),或通过时间序列分析(ARIMA模型)预测电商GMV的季度趋势。
定性分析方法
- 扎根理论:通过开放式编码、主轴编码、选择性编码三级流程,从访谈数据中提炼核心范畴,研究“老年人使用电商的障碍”,可编码出“操作复杂”(对应“界面设计不友好”“支付流程繁琐”等副范畴),最终构建“技术-心理-社会”三维障碍模型。
- 话语分析:对政策文本(如“十四五”数字经济发展规划)或企业宣传语进行话语解构,分析其隐含的价值导向。“乡村振兴背景下电商助农政策的话语体系”可揭示“效率优先”与“公平兼顾”的张力。
混合方法设计
为兼顾深度与广度,可采用“定量+定性”混合方法,先通过问卷数据识别“影响消费者选择跨境电商的关键因素”(定量),再通过深度访谈探究“消费者对海外商品质量信任度的形成机制”(定性),最终形成“现象-机制-对策”的完整逻辑。
工具应用与技术赋能
现代电子商务研究高度依赖技术工具,提升数据采集与分析效率,常见工具包括:

- 数据采集工具:Python的Scrapy框架、八爪鱼等爬虫软件,可定向抓取电商平台商品信息与用户评论;问卷星、Qualtrics用于在线问卷发放与回收。
- 数据分析工具:SPSS、Stata适用于传统统计分析;R、Python(Pandas、NumPy库)处理大规模数据;Tableau、Power BI实现数据可视化,动态展示用户画像或区域电商发展差异。
- 文本挖掘工具:Python的NLTK、LDA主题模型用于评论情感分析与主题聚类;AMOS、Mplus用于结构方程模型构建。
以下为部分工具在电商研究中的应用场景示例:
| 工具类型 | 具体工具 | 应用场景举例 |
|---|---|---|
| 爬虫工具 | Python Scrapy | 抓取淘宝某类目商品价格与销量数据 |
| 统计分析软件 | Stata | 检验“广告投入与销售额”的因果关系 |
| 可视化工具 | Tableau | 制作“各省电商渗透率热力图” |
| 文本分析工具 | LDA主题模型 | 分析京东家电用户评论中的核心问题 |
研究伦理与局限性考量
电子商务研究需严格遵守伦理规范:数据采集需匿名化处理,避免泄露用户隐私;问卷调研需获得参与者知情同意;案例研究需注明信息来源,避免商业机密争议,研究局限性需客观说明,如横截面数据无法揭示动态因果关系、样本偏差导致结论外推性受限等,为后续研究提供改进方向。
相关问答FAQs
Q1:电子商务研究中,如何平衡数据爬虫的合法性与数据获取的全面性?
A:数据爬虫的合法性需以《网络安全法》《数据安全法》及平台用户协议为前提,避免爬取敏感信息(如用户身份证号、联系方式)或违反robots协议,为平衡全面性与合法性,可采取以下策略:①优先使用平台官方API接口获取数据;②爬虫设置请求频率限制,避免对服务器造成过大压力;③对爬取数据进行脱敏处理,仅保留分析所需字段;④通过公开数据(如企业年报、行业白皮书)补充爬虫数据的缺口,确保样本覆盖广度。
Q2:在研究“直播电商用户粘性影响因素”时,如何避免问卷设计的常见偏差?
A:问卷设计偏差可能导致数据失真,可通过以下方法规避:①避免诱导性问题,如“您是否认为直播主播的专业性对您的购买决策至关重要?”(应改为中性提问“直播主播的专业性对您的购买决策影响程度如何?”);②采用量表题而非是非题,如用1-5分测量“用户对直播间的复购意愿”,减少极端选择;③预调研阶段选取30-50份小样本测试问卷,通过Cronbach's α系数检验内部一致性,删除信度过低的题项;④控制问卷长度,填写时间控制在10分钟以内,降低用户疲劳导致的随意作答概率。