核心概念:什么是队列研究?
简单回顾一下队列研究的特点:

(图片来源网络,侵删)
- 方向:从因到果,研究者先根据是否暴露于某个可疑的危险因素(如吸烟、接触某种化学物质)将研究对象分为暴露组和非暴露组。
- 前瞻性:研究者前瞻性地(forward in time)追踪这两组人群,比较他们在未来一段时间内,所研究的疾病(结局)的发生率。
- 目的:目的是检验某个暴露因素与某个疾病结局之间的因果关联。
什么是相对风险?
相对风险,也叫风险比,是队列研究中衡量暴露与疾病关联强度的核心指标。
它表示的是:暴露组人群发生某种疾病的风险,是非暴露组人群发生该疾病风险的多少倍。
RR就是比较“暴露组的风险”和“非暴露组的风险”之间的比值。
- RR = 1:表示暴露组和非暴露组的疾病风险没有差异,即暴露因素与疾病无关。
- RR > 1:表示暴露组的疾病风险高于非暴露组,即暴露因素是危险因素。
- RR < 1:表示暴露组的疾病风险低于非暴露组,即暴露因素是保护因素。
计算RR的公式
计算RR需要两个关键数据:发病率。

(图片来源网络,侵删)
第一步:计算暴露组和非暴露组的发病率
在队列研究中,我们需要建立一个经典的“四格表”来整理数据:
| 患病(发生结局) | 未患病(未发生结局) | 合计 | |
|---|---|---|---|
| 暴露组 | a | b | a + b |
| 非暴露组 | c | d | c + d |
| 合计 | a + c | b + d | N (总人数) |
- a: 暴露组中患病的人数
- b: 暴露组中未患病的人数
- c: 非暴露组中患病的人数
- d: 非暴露组中未患病的人数
我们计算两组的发病率:
- 暴露组的发病率 = 暴露组中患病的人数 / 暴露组的总人数
I_e = a / (a + b)
- 非暴露组的发病率 = 非暴露组中患病的人数 / 非暴露组的总人数
I_u = c / (c + d)
第二步:计算相对风险

(图片来源网络,侵删)
有了两个组的发病率,RR的计算就非常直接了:
RR = (暴露组的发病率) / (非暴露组的发病率) RR = I_e / I_u RR = [a / (a + b)] / [c / (c + d)]
举例说明
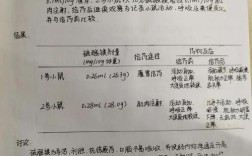
假设我们进行了一项关于“吸烟与肺癌”的队列研究,追踪了10,000名男性10年。
- 暴露组:5,000名吸烟男性
- 非暴露组:5,000名不吸烟男性
10年后,研究结果如下:
| 患肺癌 | 未患肺癌 | 合计 | |
|---|---|---|---|
| 吸烟组 (暴露组) | 150 | 4,850 | 5,000 |
| 不吸烟组 (非暴露组) | 20 | 4,980 | 5,000 |
| 合计 | 170 | 9,830 | 10,000 |
计算步骤:
-
计算吸烟组的发病率 (I_e)
- I_e = a / (a + b) = 150 / 5,000 = 03 (或 3%)
-
计算不吸烟组的发病率 (I_u)
- I_u = c / (c + d) = 20 / 5,000 = 004 (或 0.4%)
-
计算相对风险
- RR = I_e / I_u = 0.03 / 0.004 = 5
结果解读:
RR = 7.5,这意味着在本次研究中,吸烟男性患肺癌的风险是不吸烟男性患肺癌风险的7.5倍,这表明吸烟是肺癌的一个非常重要的危险因素。
重要的注意事项和补充
-
RR vs. OR (比值比)
- 在队列研究中,我们直接计算的是RR。
- 在病例对照研究中,因为我们无法计算发病率(因为我们是从已经患病和未患病的人回溯过去的暴露情况),所以我们计算的是OR (Odds Ratio)。
- 当疾病的发病率很低(比如小于10%)时,RR和OR的数值会非常接近,有时可以互换使用,但在发病率较高时,两者差异会很大。
-
RR的统计推断:置信区间
- 计算出的RR值只是一个点估计,它存在抽样误差,我们需要计算95%置信区间 (95% CI) 来判断这个结果是否具有统计学意义。
- 如何判断:如果95% CI 不包含1,则认为RR与1的差异有统计学意义(p < 0.05),即暴露因素与疾病之间存在关联,如果包含1,则认为差异无统计学意义。
- 如果上面例子中RR=7.5的95% CI是 (5.2, 10.8),因为它不包含1,所以我们有95%的信心认为吸烟确实会增加肺癌风险。
-
归因风险
- RR告诉我们风险的相对增加倍数,但没有告诉我们风险的绝对增加量。归因风险可以解决这个问题。
- AR = I_e - I_u (暴露组发病率 - 非暴露组发病率)
- 在上面的例子中,AR = 0.03 - 0.004 = 0.026,这表示,吸烟者中,有2.6%的肺癌风险可以归因于吸烟本身,这有助于我们理解该暴露因素对人群健康的公共卫生意义。
| 步骤 | 操作 | 公式/要点 |
|---|---|---|
| 明确研究设计 | 确认是队列研究(从因到果)。 | 前瞻性、有暴露组和非暴露组。 |
| 整理数据 | 制作四格表,填入a, b, c, d的数值。 | a(暴露+), b(暴露-), c(非暴露+), d(非暴露-) |
| 计算发病率 | 分别计算暴露组和非暴露组的发病率。 | I_e = a/(a+b), I_u = c/(c+d) |
| 计算RR | 用暴露组发病率除以非暴露组发病率。 | RR = I_e / I_u |
| 结果解读 | RR=1(无关联),RR>1(危险因素),RR<1(保护因素)。 | 结合95%置信区间判断统计学意义。 |
希望这个详细的解释能帮助你完全理解队列研究中RR的计算方法!