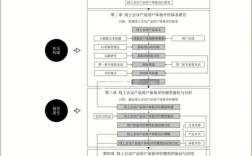
以下是评价医学研究文献的核心原则,通常围绕 “三性” 和 “三要素” 展开,并结合了具体的评价工具和流程。

(图片来源网络,侵删)
核心评价原则:三性(真实性、重要性、适用性)
这三个原则构成了评价文献的黄金标准,也是 JAMA用户指南 的核心思想。
真实性 - 研究结果是否可靠?
这是评价的第一步,旨在判断研究设计是否严谨,执行是否规范,从而最大限度地减少偏倚,不同研究类型的评价重点不同。
A. 随机对照试验
- 是否为真正的随机? 随机化方法是否明确(如计算机生成、随机数字表)?是否可以预测到分组?(区组随机、分层随机是更好的方法)。
- 是否采用了盲法? (单盲、双盲、三盲),未设盲或单盲(仅受试者设盲)更容易产生实施偏倚和测量偏倚。
- 基线特征是否可比? 干预组和对照组在人口学、病情严重程度等关键基线特征上是否相似?随机化后若出现显著差异,需警惕。
- 是否对所有受试者进行了意向性分析? 这是最重要的分析原则,无论受试者是否完成研究、是否违反方案,都应被纳入最初分配的组别进行分析,以维持随机化的优势。
- 是否报告了失访/退出情况? 失访率是否过高(gt;10%-20%)?是否对失访原因和影响进行了分析?
- 除了干预措施外,两组是否得到了同等对待? (如随访频率、关注程度等)。
B. 队列研究

(图片来源网络,侵删)
- 研究对象的确定和分组是否清晰? 暴露组和非暴露组是否在研究开始时就已明确?
- 随访时间是否足够长? 是否足以观察到结局事件的发生?
- 随访是否完整? 失访率是否过高?是否分析了失访对结果的影响?
- 结局的测量是否客观、准确? 诊断标准是否明确?是否采用了盲法进行评估?
- 在分析时是否考虑了重要的混杂因素? 是否使用了多变量分析(如Cox回归)来控制混杂偏倚?
C. 病例对照研究
- 病例组的选择是否有代表性? (如是否来自某一特定医院,导致选择偏倚)。
- 对照组的选择是否恰当? 对照组应该是产生病例的源人群的随机样本,否则会产生严重的选择偏倚。
- 病例组和对照组的测量方法是否一致? (回顾性收集暴露史时,是否采用了相同的标准和盲法?否则会产生信息偏倚)。
- 是否考虑了回忆偏倚? 病例组可能更倾向于回忆过去的暴露史。
- 是否匹配了重要的混杂因素? 匹配过头也是一个需要警惕的问题。
D. 诊断性试验研究
- 是否与“金标准”进行独立、盲法比较? 这是诊断试验评价的基石,待评价试验和金标准的操作和判读应相互独立,且操作者不知晓金标准结果,反之亦然。
- 研究对象是否包含临床实践中各种类型的患者? (包括轻症、重症、合并症等),即是否包含了“疾病谱”和“谱偏倚”。
- 样本量是否足够?
重要性 - 研究结果有多大临床价值?
如果研究结果是真实的,那么它的影响有多大?主要看效应大小和精确度。
- 效应大小:
- RCT/队列研究: 看 相对危险度、比值比 或 风险差,RR/OR > 1 表示风险增加,< 1 表示风险降低,RD则直接反映了绝对风险的变化。
- 诊断试验: 看 敏感性(真阳性率)、特异性(真阴性率)、阳性预测值、阴性预测值。
- 连续性变量: 看 均数差 或 标准化均数差。
- 结果的精确度:
- 看置信区间,CI的范围越窄,结果越精确,随机误差越小。
- 临床解读:
- CI不包含无效值(如RR=1,OR=1,差值为0):说明结果具有统计学意义。
- CI范围具有临床意义:即使有统计学意义,CI的下限和上限是否包含了有临床意义的值?一种新降压药,RR=0.95 (95% CI: 0.90-1.01),虽然统计学上不显著(包含1),但其下限0.90也提示可能有一定临床获益,值得进一步研究。
- CI范围过宽:说明样本量不足,结果不精确,无法得出可靠结论。
适用性 - 结果能否应用于我的患者?
这是将研究结果转化为临床实践的关键一步,即外部效度的评估。
- 我的患者与研究对象是否相似?
- 人口学特征: 年龄、性别、种族等。
- 病情特征: 疾病类型、严重程度、病程、合并症等。
- 生物学特征: 基因型、病理类型等。
- 我的医疗环境与研究环境是否相似?
- 医疗资源: 药物 availability、设备、技术水平、医护人员经验等。
- 医疗体系和文化: 医疗费用、患者依从性、社会文化背景等。
- 研究结果是否利大于弊?
- 考虑患者的价值观和偏好: 患者更看重延长生命还是提高生活质量?对副作用的耐受度如何?
- 权衡成本效益: 新的治疗方法或诊断技术是否成本过高?
- 是否考虑了所有备选方案? 是否将此研究结果与现有的、成熟的诊疗方案进行了比较?
评价医学研究的“三要素”
除了“三性”原则,在阅读文献时,始终要关注构成一篇完整研究的三个基本要素:
- 研究对象: 他们是谁?如何招募?纳入和排除标准是什么?样本量如何确定?样本的代表性如何?
- 研究干预/暴露: 研究中具体做了什么?干预措施的内容、剂量、频率、持续时间是否清晰明确?对照组的设置是否合理?
- 研究结局: 观察或测量了什么?结局指标的选择是否科学、客观?测量方法是否可靠、有效?随访时间是否足够长以观察到结局?
评价工具与流程
为了系统地进行评价,可以使用一些结构化工具和流程。
常用评价工具
- CASP (Critical Appraisal Skills Programme) 工具集: 提供针对不同研究类型(RCT、系统评价、队列研究等)的清单式问题,非常实用。
- JAMA用户指南: 提供了针对不同研究类型的“用户指南”,帮助临床医生快速理解和评价。
- ROBINS-I (Risk Of Bias In Non-randomized Studies - of interventions): 用于评价非随机干预性研究的偏倚风险。
- QUADAS-2 (Quality Assessment of Diagnostic Accuracy Studies 2): 用于评价诊断性研究的质量。
评价流程建议
- 初筛: 阅读标题和摘要,判断研究主题是否与你的问题相关,研究设计是否恰当。
- 通读全文: 快速阅读全文,了解研究的基本框架、主要方法和核心发现。
- 精读与批判:
- 研究方法部分: 严格运用“真实性”原则,检查研究设计、实施和分析的每一个环节。
- 结果部分: 提取关键数据,计算并理解效应大小和置信区间,评估“重要性”。
- 讨论部分: 思考作者对结果的解释是否合理?是否承认了研究的局限性?其结论是否被数据所支持?
- 综合判断: 结合“适用性”原则,思考研究结果如何应用于你的临床实践,并为你的患者做出最佳决策。
评价医学文献是一个动态的、批判性的思维过程,它没有绝对的“好”与“坏”,只有“证据等级”的高低和“适用性”的强弱,掌握上述原则和工具,将帮助你从海量信息中筛选出高质量、高价值的证据,从而做出更科学、更人性化的临床决策。