是项目的核心组成部分,需要系统、清晰地阐述研究的具体方向、实施路径和预期成果,既要体现学术严谨性,也要突出实践价值,以下从研究背景与问题提出、研究目标与核心内容、研究方法与技术路线、预期成果与价值分析四个维度展开详细说明,并辅以表格呈现关键信息,最后附相关FAQs。

研究背景与问题提出 的设定需基于现实需求或理论空白,在“基于人工智能的慢性病风险预测模型研究”项目中,首先需明确我国慢性病防控形势严峻:据《中国慢性病防治中长期规划(2025-2025年)》,心脑血管疾病、糖尿病等慢性病导致的死亡人数占总死亡人数的88.5%,疾病负担占总疾病负担的70%以上,现有风险预测工具多依赖传统统计模型(如Logistic回归),存在特征提取不全面、动态更新能力弱、个体化精度不足等问题,本研究拟通过融合多源医疗数据与深度学习算法,构建更精准的慢性病风险预测模型,为早期干预提供技术支撑,这一逻辑链条需清晰呈现“现实需求—现存问题—研究切入点”的递进关系,为后续研究内容奠定合理性基础。
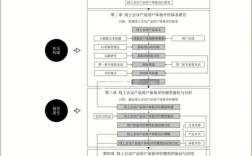
研究目标与核心内容
研究目标是研究内容的纲领性指引,需具体、可衡量,以慢性病预测模型为例,总体目标可设定为:开发一套融合电子健康档案(EHR)、可穿戴设备数据和生活方式问卷的多模态慢性病风险预测系统,实现预测准确率较传统模型提升15%以上,并在3家基层医疗机构试点应用。
需分解为若干子模块,形成层次化研究框架:
多源数据融合与特征工程
- 数据采集与标准化:整合三甲医院HIS系统(诊断记录、检验结果)、区域卫生平台(人口学信息、既往病史)、可穿戴设备(心率、步数、睡眠质量)及结构化问卷(饮食、运动、吸烟饮酒习惯)等数据源,制定统一的数据标准(如采用ICD-10编码、LOINC检验术语),解决异构数据格式不兼容问题。
- 特征提取与降维:通过相关性分析剔除冗余特征,利用基于注意力机制的深度学习模型(如LSTM-Attention)提取时序特征(如血压波动趋势),结合LightGBM算法筛选关键预测因子(如年龄、BMI、空腹血糖、运动频率等),构建特征重要性排序表。
基于深度学习的预测模型构建
- 模型选择与优化:对比多种深度学习架构的性能,包括卷积神经网络(CNN,处理空间特征如检验指标组合)、循环神经网络(RNN,处理时序数据如病程记录)及Transformer模型(捕捉长距离依赖关系),采用集成学习策略(如模型加权投票)提升鲁棒性。
- 动态更新机制:设计在线学习框架,当新数据累积超过10%时触发模型迭代,通过知识蒸馏技术保留旧模型知识,避免“灾难性遗忘”,确保模型适应疾病谱变化。
模型验证与临床转化
- 验证方案:采用回顾性队列(某三甲医院2025-2025年10万份电子病历)与前瞻性队列(3家社区中心2025-2025年招募5000名志愿者)双重验证,评价指标包括AUC-ROC、精确率、召回率、校准度等,与传统Framingham评分模型进行交叉对比。
- 可视化交互系统开发:基于Web技术搭建用户友好型平台,向医生展示风险等级(高/中/低)、关键影响因素及干预建议,向患者提供个性化健康报告,实现“预测-预警-干预”闭环。
伦理与安全机制研究
- 制定数据脱敏方案(如差分隐私技术),确保患者隐私符合《个人信息保护法》;建立模型决策可解释性模块(如SHAP值可视化),避免“黑箱”问题导致的临床信任危机。
研究方法与技术路线
研究方法需科学、可操作,技术路线需清晰展示逻辑流程,可采用表格形式呈现关键步骤:
| 研究阶段 | 具体方法 | 技术工具/平台 | 时间节点 |
|---|---|---|---|
| 数据收集 | 多中心横断面调查+回顾性病历提取+前瞻性队列随访 | Epic HIS系统、华为运动健康API | 第1-6个月 |
| 数据预处理 | 缺失值插补(多重插补法)、异常值检测(3σ原则)、标准化(Z-score) | Python (Pandas, Scikit-learn) | 第7-9个月 |
| 模型构建 | 超参数优化(贝叶斯优化)、交叉验证(5折)、对比实验(vs. LR, SVM, XGBoost) | TensorFlow 2.0, PyTorch, MLflow | 第10-15个月 |
| 系统开发 | 前端(Vue.js+ECharts)、后端(Spring Boot+MySQL)、部署(Docker+K8s) | JIRA项目管理、Git版本控制 | 第16-18个月 |
| 临床验证 | 敏感性分析、亚组分析(年龄/性别分层)、成本效益评估 | R (p包、Survival包) | 第19-24个月 |
技术路线图可描述为:“数据采集→标准化处理→特征工程→模型训练与优化→系统开发→临床验证→成果产出”,形成完整闭环。
预期成果与价值分析
预期成果需区分理论成果、应用成果及社会经济效益,体现研究的综合价值。

理论成果
- 构建1套慢性病多模态数据融合框架,发表SCI/SSCI论文2-3篇(IF≥5);
- 提出1种基于动态学习的模型更新方法,申请发明专利1项(名称:“一种自适应慢性病风险预测模型的更新方法”);
- 形成1套《人工智能辅助慢性病预测模型应用指南》(行业标准草案)。
应用成果
- 开发1款慢性病风险预测软件系统(V1.0),获得软件著作权1项;
- 在3家基层医疗机构部署应用,覆盖目标人群1万人,形成可复制的“AI+基层医疗”推广模式;
- 培训基层医生50人次,提升慢性病早期识别能力。
社会经济效益
- 通过早期干预降低慢性病并发症发生率,预计试点区域人均医疗支出减少12%;
- 为公共卫生部门提供疾病风险地图,辅助资源优化配置,提升防控效率。
相关问答FAQs
Q1: 研究内容中如何平衡创新性与可行性?
A1: 创新性体现在技术融合(如多模态数据+动态学习模型)和方法突破(如在线知识蒸馏解决模型遗忘问题),可行性则通过分阶段实施保障:前期依托合作医院的历史数据完成基础模型训练,中期采用成熟的开源框架(如TensorFlow)降低开发难度,后期通过小范围试点验证实用性,同时预留充足时间应对伦理审批、数据获取等潜在风险,组建包含临床医生、数据科学家、伦理专家的跨学科团队,确保研究方向既符合临床需求,又具备技术落地条件。
Q2: 若研究过程中数据质量不达标(如可穿戴设备数据缺失率过高),如何调整研究内容?
A2: 预设数据质量评估机制,若某类数据缺失率超过30%,则启动备选方案:① 增强传统数据源(如补充电话随访问卷),减少对可穿戴设备的依赖;② 采用生成对抗网络(GAN)进行数据合成,填补缺失值;③ 调整模型权重,降低低质量数据在特征工程中的占比,在立项申请书中明确“数据质量应急预案”,体现研究的灵活性和严谨性,确保核心目标(预测模型构建)不受显著影响。