如何论述自己的论文研究过程
论述研究过程的核心是展示你研究的科学性、逻辑性和严谨性,你需要清晰地回答以下问题:“你是如何想到这个问题的?你为了解决这个问题,具体做了哪些工作?你的每一步工作是如何为最终结论服务的?”

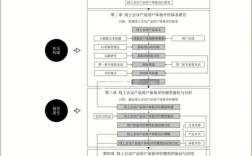
一个完整的研究过程论述通常可以分为以下六个核心阶段,你可以按照这个逻辑线来组织你的陈述。
论文研究过程论述框架
第一阶段:问题发现与课题确立
这是研究的起点,也是你研究的价值所在,你需要阐明你“为什么”要做这个研究。
论述要点:
-
研究背景:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 描述你所研究领域的宏观背景,是人工智能、市场营销、还是历史社会学?
- 指出当前领域内存在的普遍现象、趋势或亟待解决的问题。
- 举例: “随着深度学习技术在图像识别领域的广泛应用,其在医疗影像诊断中也展现出巨大潜力,现有模型在处理罕见病或边缘病例时,仍存在准确率不高、可解释性差等问题。”
-
问题提出:
- 在上述背景下,具体化你的研究问题,这个问题应该是具体的、清晰的、有研究价值的。
- 说明为什么这个问题值得研究,它填补了哪些空白?解决了哪些痛点?
- 举例: “本研究聚焦于如何提升医学影像模型在识别罕见病时的准确率,并探索一种能够解释其决策过程的可视化方法,以增强医生对AI辅助诊断的信任。”
-
研究意义:
- 理论意义: 你的研究对现有理论有何补充、修正或发展?
- 实践意义/应用价值: 你的研究成果能解决什么现实问题?对行业、社会或特定群体有何帮助?
- 举例: “本研究在理论上,为小样本学习领域的模型优化提供了新思路;在实践上,有望提高罕见病的早期诊断率,降低漏诊、误诊风险。”
-
研究目标与内容:
- 研究目标: 清晰地列出你希望通过研究达成的具体目标(通常2-4条)。
- 为了实现这些目标,你需要研究哪些具体方面?这通常对应你论文的章节结构。
- 举例:
- 目标1: 设计并实现一个基于注意力机制的新型卷积神经网络,以提高罕见病影像的分类准确率。
- 目标2: 开发一种模型决策过程的可视化工具,增强模型的可解释性。
- 目标3: 通过公开数据集和模拟临床数据,验证所提方法的有效性和实用性。
第二阶段:文献综述与理论基础
这一阶段展示你站在“巨人的肩膀上”,为你的研究找到了坚实的理论支撑和前人的经验。

论述要点:
-
核心概念界定:
- 定义你论文中的关键术语和核心概念,确保研究的边界清晰。
- 举例: “本研究中的‘罕见病影像’,特指发病率低于1/20万,且在常规数据集中样本量少于100例的医学影像。”
-
国内外研究现状梳理:
- 分类总结: 将现有研究按照不同的方法、流派或角度进行分类。“根据模型架构,现有方法可分为A类和B类;根据应用场景,可分为C类和D类。”
- 评述与分析: 不仅要“述”,更要“评”,指出各类研究的优点和局限性。
- 举例: “A类方法(如ResNet)在通用图像识别上表现优异,但在处理罕见病这类小样本问题时,容易过拟合,B类方法(如迁移学习)通过预训练缓解了这一问题,但其决策过程如同‘黑箱’,难以被医生理解。”
-
述评与研究切入点:
- 总结现有研究的整体状况,明确指出研究空白或不足之处。
- 这一步至关重要,它直接论证了你研究的创新性和必要性。
- 举例: “当前研究或侧重于准确率而忽略可解释性,或虽兼顾二者但效果不佳,本研究将准确率和可解释性作为两个核心优化目标,旨在设计一个兼顾二者的新型模型框架,这正是本研究的创新点和切入点。”
第三阶段:研究设计与方法
这是你研究的“施工蓝图”,详细说明你“如何”开展研究。
论述要点:
-
研究范式/路线图:
- 用一张清晰的流程图展示你研究的整体技术路线或逻辑框架。
- 举例: “本研究采用‘理论构建-模型设计-实验验证-结果分析’的技术路线,基于注意力机制理论构建模型框架;设计并实现模型;在公开数据集上进行实验;通过对比分析和消融实验验证模型的有效性。”
-
研究对象与数据来源:
- 研究对象: 明确你的研究对象是什么(如特定人群、文本语料、公司财报等)。
- 数据来源: 详细说明你的数据从何而来(如公开数据集、问卷调查、企业合作、爬虫获取等)。
- 数据处理: 描述你如何对原始数据进行清洗、预处理、标注和划分(如训练集、验证集、测试集的比例)。
-
研究工具与模型构建:
- 工具: 列出你使用的软件、编程语言、统计工具、硬件设备等。
- 模型/方法设计: 这是核心部分,详细阐述你提出的模型、算法或理论框架的核心思想、结构和工作原理,可以配以示意图、公式或伪代码来辅助说明。
- 举例: “本研究提出的‘Attention-XNet’模型,在标准ResNet-50的基础上,引入了两个关键模块:1) 空间-通道双重注意力模块,用于自适应地聚焦于病灶区域;2) 基于Grad-CAM++的可解释性生成模块,用于可视化模型关注的图像区域。”
第四阶段:数据收集与实验过程
这是将蓝图付诸实践的具体操作阶段,展示你研究的可重复性。
论述要点:
-
数据收集过程:
- 具体描述你如何获取数据,遇到了哪些困难以及如何解决的。
- 举例: “我们从国家医学影像数据库和Kaggle平台获取了包含5种罕见病的共计10,000张影像,由于部分数据质量不佳,我们通过Python编写脚本去除了模糊和标签错误的图像,最终得到有效数据8,500张。”
-
实验设置:
- 基线模型: 选择了哪些经典的或先进的模型作为对比基准?为什么选择它们?
- 评价指标: 你用什么指标来衡量你的模型或方法的好坏?(如准确率、精确率、召回率、F1分数、RMSE等)。
- 参数设置: 关键的超参数(如学习率、批次大小、迭代次数)是如何设定的?为什么这样设定?
-
实验执行过程:
简要描述实验的执行流程。“我们在配置为NVIDIA RTX 3090的GPU服务器上,使用PyTorch框架进行模型训练,训练过程分为三个阶段:...”
第五阶段:结果分析与讨论
这是你研究的“收获季”,展示你的研究发现并赋予其意义。
论述要点:
-
结果呈现:
- 客观、清晰: 使用图表(如折线图、柱状图、混淆矩阵)来直观地展示你的实验结果。
- 数据说话: 用数据说话,说明你的模型/方法在各项指标上均优于基线模型。“如表3-1所示,本模型的准确率达到95.2%,比最优基线模型高出2.8个百分点。”
-
结果分析:
- 深入解读: 不仅仅是罗列数据,更要解释数据背后的含义,为什么你的方法会取得这样的效果?
- 对比分析: 将你的结果与文献综述中提到的其他研究进行对比,突出你的优势。
- 举例: “我们观察到,在测试集上,本模型对样本最稀少的‘疾病E’识别准确率提升最为显著(+5%),这说明我们提出的注意力机制能更有效地从少量样本中学习关键特征。”
-
讨论:
- 验证假设: 你的研究结果是否验证了你在研究设计阶段提出的假设?
- 解释意外发现: 实验中是否有你未曾预料到的结果?如果有,尝试解释其原因。
- 与理论对话: 你的发现如何支持、挑战或发展了现有的理论?
第六阶段:研究结论与展望
这是对整个研究的总结和升华。
论述要点:
-
研究结论:
- 用简洁、概括的语言,分点总结你的研究工作和主要发现。
- 结论应与引言中的研究目标相呼应,证明你完成了既定任务。
- 避免引入新信息。
-
研究创新点:
再次强调你的研究在理论、方法或应用层面的主要贡献和独特之处。
-
研究局限性与未来展望:
- 局限性: 诚实地指出你研究的不足之处,这体现了你的科学严谨和批判性思维。“本研究仅使用了公开数据集,未来将在更大规模、更多样化的真实临床数据上进行验证。”
- 展望: 基于你的局限性和研究发现,提出未来可以进一步研究的方向,这为后续研究者提供了思路。
范例:一个简化的研究过程陈述
** 《基于注意力机制和可解释性增强的罕见病医学影像诊断模型研究》
我的研究过程主要分为以下六个步骤:
第一,问题确立。 我发现,虽然AI在医疗影像诊断上很火,但它在识别罕见病时,因为样本少,效果不好,而且医生也搞不懂AI为什么这么判断,不敢用,我的研究就是要解决“如何让AI又准又明白地诊断罕见病”这个问题,这既能让诊断更准,又能让医生放心用。
第二,文献梳理。 我看了很多文献,发现大家要么只追求准确率,但模型是“黑箱”;要么尝试做可解释性,但准确率又下降了,这两者没有很好地结合起来,这就是我的研究切入点:我要做一个既准又明白的模型。
第三,方法设计。 基于这个想法,我设计了我的模型,叫“Attention-XNet”,它的核心就是两个模块:一个是“注意力模块”,让它能像老专家一样,自动找到图像里的关键病灶;另一个是“可解释性模块”,它能用热力图把AI的思考过程“画”出来,让医生一目了然。
第四,实验过程。 我从公开数据集里找了8000多张罕见病影像,把它们分成训练集和测试集,我对比了ResNet等几个主流模型,用准确率和F1分数来衡量,我的实验是在一台高性能GPU上跑的,花了两周时间。
第五,结果分析。 实验结果非常好,我的模型准确率达到95.2%,比最好的对比模型还高2.8%,特别是在样本最少的病种上提升最大,这说明我的注意力模块确实有效,生成的热力图也显示,模型关注的地方和医生诊断的病灶区域高度吻合,证明它确实“明白”自己在看什么。
第六,结论与展望。 我成功地设计并验证了一个兼顾高准确率和强可解释性的模型,我的研究也有局限,比如数据量还不够大,我希望能在真实的医院里测试这个模型,并且把它做得更轻便,方便在普通电脑上运行。